Partitioning
Partitions (sharding) can be understood as substreams. It enables streams to scale horizontally.
Currently partitions don’t have well-defined rate limits, but future versions of the P2P network may enforce limits. For now, we recommend not exceeding around 100 msg/sec/partition.
For streams that need to handle large data rates, partitions are used for sharding of the data. Sharding data simply means dividing a large volume of messages to multiple partitions.
Partitions are a way for subscribers to load balance data from a stream over a number of consuming processes, up to the number of partitions. So if a stream has 5 partitions, the user could start up to 5 independent subscribers on separate physical machines, with each subscriber receiving different messages (each process subscribes to a unique partition).
Think of it like a large river can split the same amount of water to multiple smaller branches.
Each partition shares the general properties of the parent stream, such as name, description, and user permissions.
However, the partitions behave independently when it comes to delivering and storing data in the Streamr Network, which allows for scalability.
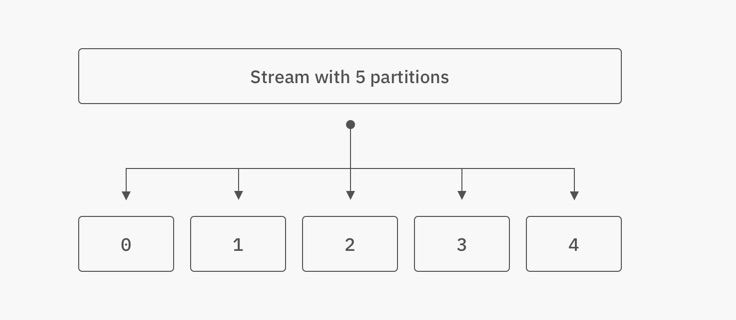
When messages are published to a stream, they are actually published to a partition within that stream. One partition per stream is the default, which is sufficient for streams with moderate rates of data (approx. less than 100 msg/sec).
Create partitioned streams
Create new partions if your messages extend approx. 100 msg/sec per partition.
By default, streams only have 1 partition when they are created. The partition count can be set to any number between 1 and 100. An example of creating a partitioned stream:
// Requires MATIC tokens (Polygon blockchain gas token)
const stream = await streamr.createStream({
id: `/foo/bar`,
partitions: 10,
});
console.log(
`Stream created: ${stream.id}. It has ${
stream.getMetadata().partitions
} partitions.`
);
Publish to partitioned streams
In most use cases, a user wants related messages (e.g. messages from a particular device) to be assigned to the same partition, so that the messages retain a deterministic order and reach the same subscriber(s) to allow them to compute stateful aggregates correctly.
If stream has been setup to have only one partition and no partition key is specified while publishing, the data goes to partition 0 by default. However, if stream has been set to have multiple partitions and no partition key is given the partition will be selected randomly from the range between 0 and partition count minus 1 .
You can specify the partition number as follows:
await streamr.publish(
{
id: `${address}/foo/bar`,
partition: 4,
},
msg
);
Add partition keys
A common approach is to utilize a partition key. A partition key is a value chosen from the data which is used to determine the partition of the message.
For example a customer ID could be used as a partition key in an application that publishes customer interactions to a stream. In an IoT use case, the device id can be used as partition key.
The same partition key always maps to the same partition.
This way, all messages from a particular customer always go to the same partition. This is useful because it keeps all the events related to a particular customer in a single and known partition instead of spreading them over all partitions.
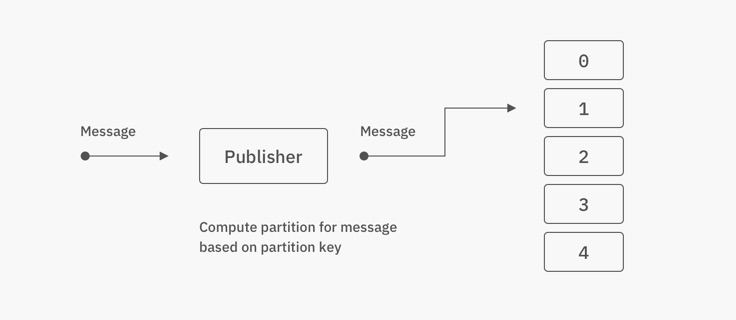
The partition key can be given as an argument to the publish methods, and the library assigns a deterministic partition number automatically:
await stream.publish(msg, {
partitionKey: msg.vehicleId,
});
Subscribe to partitioned streams
By default, the Streamr SDK is configured to subscribe to the first partition (partition 0) of a stream.
The partition number can be explicitly given in subscribe:
const sub = await streamr.subscribe(
{
id: streamId,
partition: 4,
},
(content) => {
console.log('Got message %o', content);
}
);
Subscribe to multiple partitions:
const onMessage = (content, streamMessage) => {
console.log(
'Got message %o from partition %d',
content,
streamMessage.getStreamPartition()
);
};
await Promise.all(
[2, 3, 4].map(async (partition) => {
await streamr.subscribe(
{
id: streamId,
partition,
},
onMessage
);
})
);